Open Research Platform
Open Research Platform diagram highlighting the areas targeting the demonstrations goes here
Coordinated Demonstrations
1. Workload characterisation and performance modelling methods
Objectives:
- Demonstrate general methods for extracting application attributes, including target-dependent attributes (e.g. performance) and target-independent attributes (e.g. number of multipliers, store and load operations)
- Demonstrate how performance models can be generated to estimate exascale workload performance
- Demonstrate simulation infrastructure (?)
Partners:
- IMP (Leader): workload characterisation and performance modelling
- UVA: workload characterisation and performance modelling
- TSI (?): workload characterisation
- CAM: application support
- MAX/SYN (?): application support
Applications: DMC, Asian Option Pricing (?), Retinal Image Segmentation (?)
Related Tasks: T2.3, T3.4
Relation to the Open Research Platform:
- Input to the Platform
- Performance monitoring and prediction module
- Hardware platform model?
Evaluation Platform: Maxeler DFEs, TBD
Resources:
- Exascale Workload Characterization and Architecture Implications (paper)
- A Tool for Bottleneck Analysis and Performance Prediction for GPU-accelerated Applications
2. CAOS Tools Platform
Objectives:
- Demonstrate ...
- Demonstrate ...
Partners:
- PDM(Supreme Leader): main developers of CAOS
- IMP: hardware estimation
- UVA: optimal off-loading CPU-FPGAs
- GNT: polyhedral analysis and transformations
- MAX/SYN: application support
Applications: Asian Option Pricing, Retinal Image Segmentation
Related Tasks: T2.3, T3.2, T4.2, T4.3
Relation to the Open Research Platform: - CAOS tools platform
Evaluation Platform: Zynq board?
Resources:
3. Virtual Reconfigurable Architecture
Objectives:
- Demonstrate implementation VCGRA on a physical FPGA
- Show the benefits of TLUTs and TCONs
Partners:
- Ruhr University Bochum
- Ghent University
- Synelexis
Applications:
- Vessel Segmentation (SYN)
Related Tasks:
- WP2 T2.3
- WP5 T5.3
- WP7 T7.1
Relation to the Open Research Platform:
We mainly realize an additional tool flow, which combines a coarse grained overlay architecture and the TLUT/TCON tool flow for the efficient implementation.
- Pre-Frontend: Creation of a VCGRA from an PE definition and an interconnection definition
- Frontend: Mapping a given application onto a VCGRA
- Implementation: TCON/TLUT tool flow for efficient implementation on real/virtual FPGAS
- Backend: Vendor tools for simulation and Implementation on FPGAs
Our tools and the tools from Ghent University need to be integrated into the open exploration platform.
We plan to provide a further design approach for reconfigurable systems
- Adjustable granularity, based on application demands
- Dynamic reconfiguration as an inherent part of the design
- Library of reusable processing elements for specific application classes
Evaluation Platform:
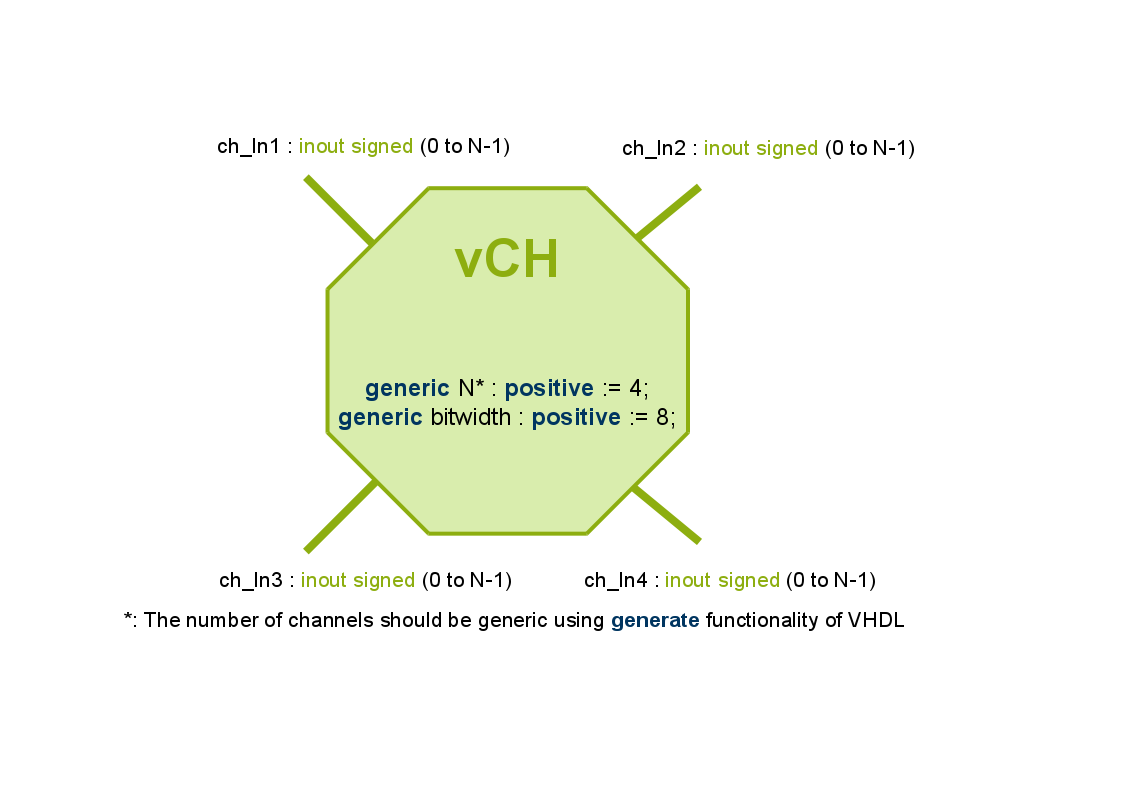
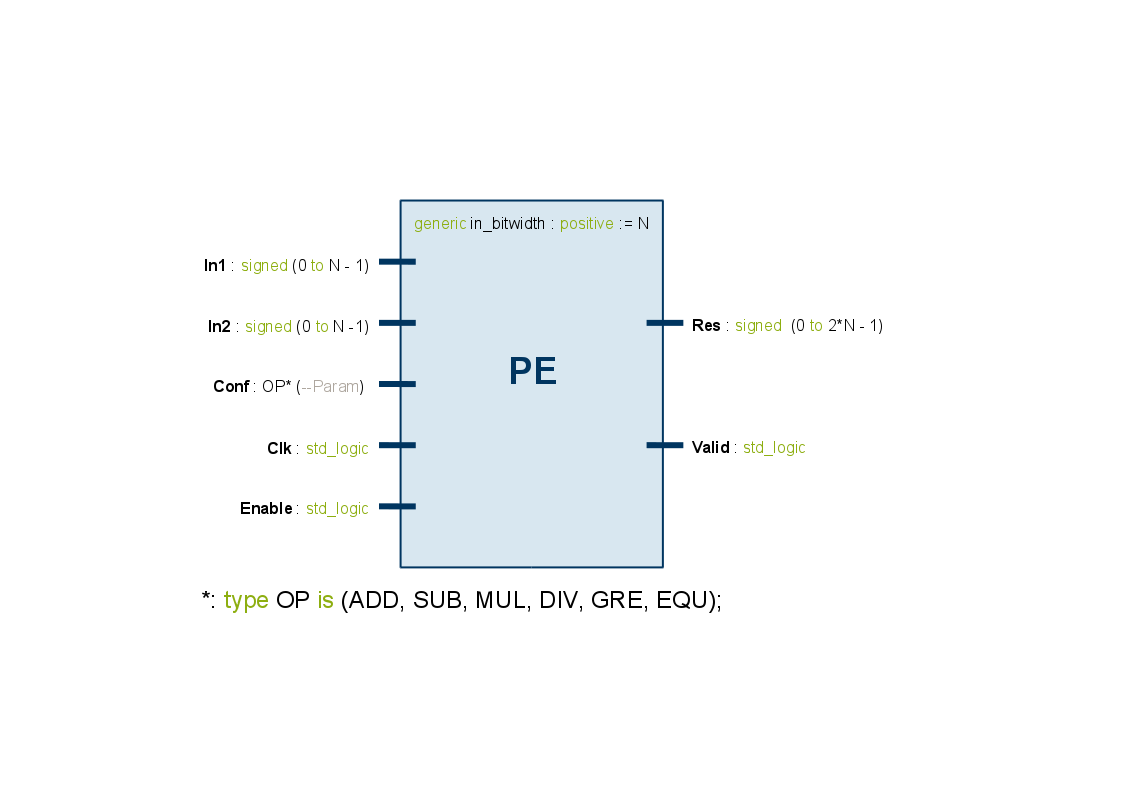
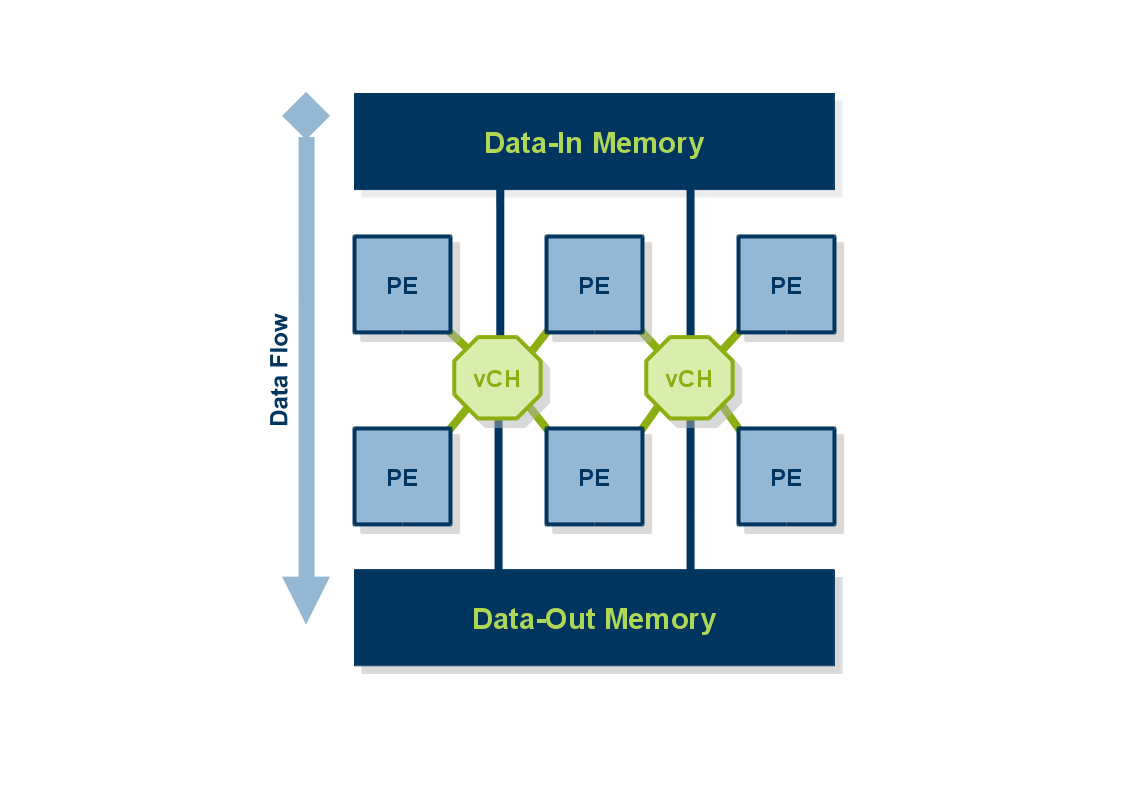
3 stage concept:
1) Static implementation of a VCGRA using Vivado® synthesis flow
- Showing the possibilities of using VCGRA on an FPGA providing mathematical operations
- Having a running application (SYN – vessel segmentation) to show during review meeting
- Getting baseline values for area and performance
2) Reconfigurable implementation of a VCGRA using TLUT synthesis flow
- Showing benefits of reconfiguration using dynamic circuit specialization (area, performance)
- Having a running application on a physical FPGA
3) Reconfigurable implementation of a VCGRA using TCON synthesis flow
- Showing final tool flow providing information about area benefits on a hypothetical FPGA
Resources:
We work with Xilinx Vendor tools (Vivado, ISE) and we plan to implement our design on a Zedboard or a VirtexV. This is caused by the fact, that the TLUT tool flow is currently only supported on these platforms.